便捷添加反引号插件
我个人是 Markdown 的深度使用者,但是在写 Markdown 的时候发现手动添加反引号是一件非常麻烦的事情。包括两种情况:一种是单行代码的两个反引号;另一种是使用两组一共六个反引号包含的代码块。因此花了半天研究了一下 VSCode 的插件开发流程,写了这个简易的小插件。
Features
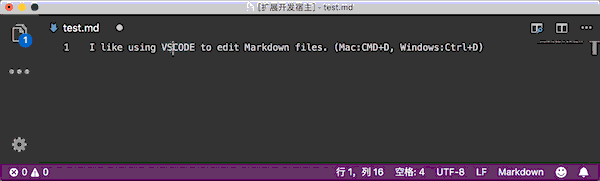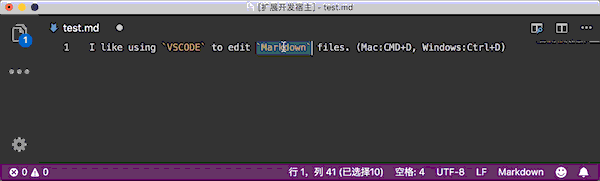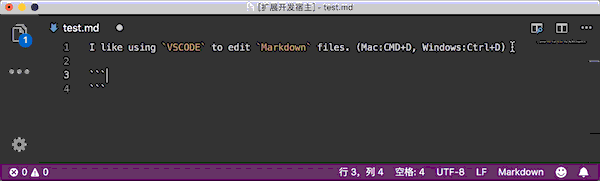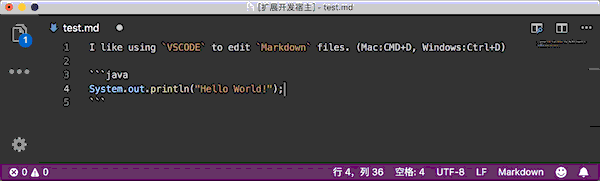
对于选中的文本使用插件会添加单行代码的反引号,不选中文本的情况下会在当前的文本的下一行自动插入代码块的反引号。
使用快捷键添加(推荐):
- Mac:
cmd+d - Windows:
ctrl+d
安装
Release Notes
0.0.1 (2018/11/11)
- 初始版本
0.0.2
- 添加自动生成代码块反引号功能
更多
如果有更好的建议可以在 Github 或者个人博客留言,后续还会添加更多的功能
Enjoy!
Markdown Add Backquote
I am a markdown deep user.When writing markdown files, it is very troublesome thing to add backquote manually.There are two scenarios: one is the two backquote of a single line of code;The other is the block of code contained six backquote.So we used half a day to develop this simple plugin.
Features
The selected content will be added to the line backquote.If you do not select text, plugin will add code block backquote.
Use shortcut keys to add backquotes in Markdown:
- Mac:
cmd+d - Windows:
ctrl+d
Install
Release Notes
0.0.1 (2018/11/11)
- First version
0.0.2
- Add auto generated code block backquote function.
For more information
If you have better suggestions, you can leave a message on Github or my personal blog, and more features will be added later.
Enjoy!
本文由 zealzhangz 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为:
2018/11/15 20:29
