
背景
优化SQL过程中大家会发现一个规律,逻辑相对较复杂SQL优化的空间相对较大,优化起来思路相对也是比较多的。 尝试优化下面的SQL:
SELECT count(*) FROM big_table;
直接运行的结果(数据库引擎为innoDB):
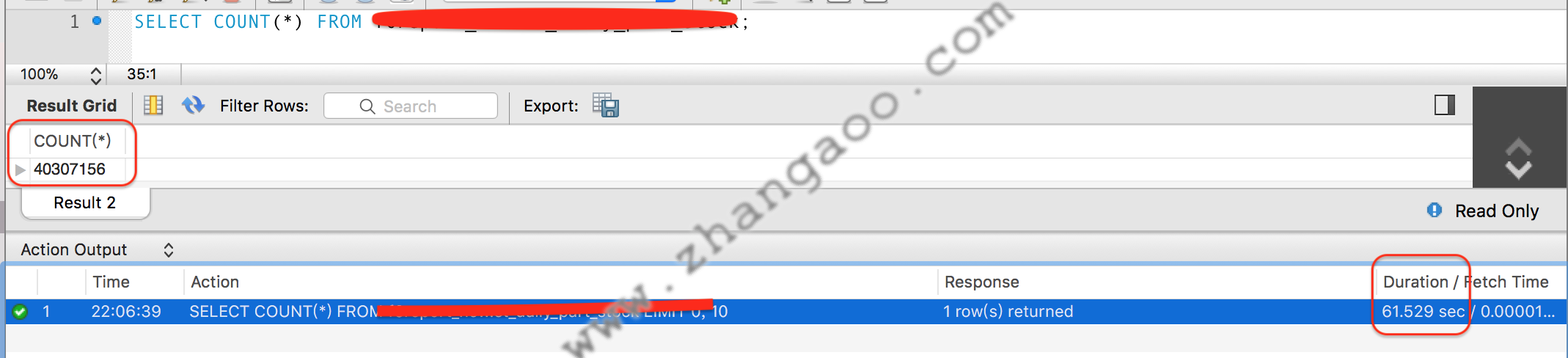 你能想到哪些优化思路呢?这里给出几种可能的思路,但不一定适合所有业务场景。
你能想到哪些优化思路呢?这里给出几种可能的思路,但不一定适合所有业务场景。
- 在表中添加而外的字段记录COUNT(*)的值,插入一条数据就+1,删除一条数据就-1,也可以使用触发器完成加减的任务。
- 假设业务表的主键id是自增的且不会删除数据,可以根据id计算当前表中的行数
- 更换数据库引擎,比如MyISAM
- 使用EXPLAIN可得到近似值
EXPLAIN SELECT COUNT(id) FROM data USE INDEX (PRIMARY)
这就引出今天要讨论的话题 MySQL分区能否解决以上问题??
MySQL分区功能简介
概念
我理解的表分区把一张大表拆分成N个规模较小的子表,这些子表对用户透明,但是使用上有一些规则和技巧。
分区的类型
- 范围分区(RANGE Partitioning)
- 列表分区(LIST Partitioning)
- 列分区 (COLUMNS Partitioning)
- 哈希分区(HASH Partitioning)
- 键值分区(KEY Partitioning)
简单介绍常用的三种分区方式
范围分区示例1:
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
/*1<=store_id<=5*/
PARTITION p0 VALUES LESS THAN (6),
/*6<=store_id<=10*/
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
/*PARTITION p3 VALUES LESS THAN (21)*/
PARTITION p3 VALUES LESS THAN MAXVALUE
);
说明: 1、RANGE括号里必须包含一个返回整数的表达式,叫做分区表达式。比如:YEAR(separated)、UNIX_TIMESTAMP(report_updated)等。 2、分区区间大小是必须递增的,也就是说是有顺序
列表分区示例2:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);
说明: 列表分区的区间可以无顺序
列分区示例3:
#按字符串比较
CREATE TABLE employees_by_lname (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE COLUMNS (lname) (
PARTITION p0 VALUES LESS THAN ('g'),
PARTITION p1 VALUES LESS THAN ('m'),
PARTITION p2 VALUES LESS THAN ('t'),
PARTITION p3 VALUES LESS THAN (MAXVALUE)
);
#按元祖大小
CREATE TABLE rcx (
a INT,
b INT,
c CHAR(3),
d INT
)
PARTITION BY RANGE COLUMNS(a,d,c) (
PARTITION p0 VALUES LESS THAN (5,10,'ggg'),
PARTITION p1 VALUES LESS THAN (10,20,'mmm'),
PARTITION p2 VALUES LESS THAN (15,30,'sss'),
PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE,MAXVALUE)
);
说明:
- 列分区是范围和列表分区上的变体,列分区允许在分区键中使用多个列。
- 元组的大小是有顺序的,在不确定元组大小顺序时,可使用如下SELECT语句进行测试。例如:SELECT ROW(5,10) < ROW(5,12), ROW(5,11) < ROW(5,12), ROW(5,12) < ROW(5,12);
- 在创建这样的表之后,更改给定的数据库、表或列的字符集或排序规则可能会导致行分布的更改。
- 分区名称不区分大小写。
注意:以上表无主键,有主键或唯一键的情况又是怎样的呢?下面会介绍表分区的规则
分区的基本规则
带分区的表无主键、无唯一键分区表达式可以使表中的任何一列。
如上面的示例
有主键、一个或多个唯一键
All columns used in the partitioning expression for a partitioned table must be part of every unique key that the table may have.
分区表达式中使用的所有列必须是表的每个唯一键的一部分。
实践MySQL分区功能
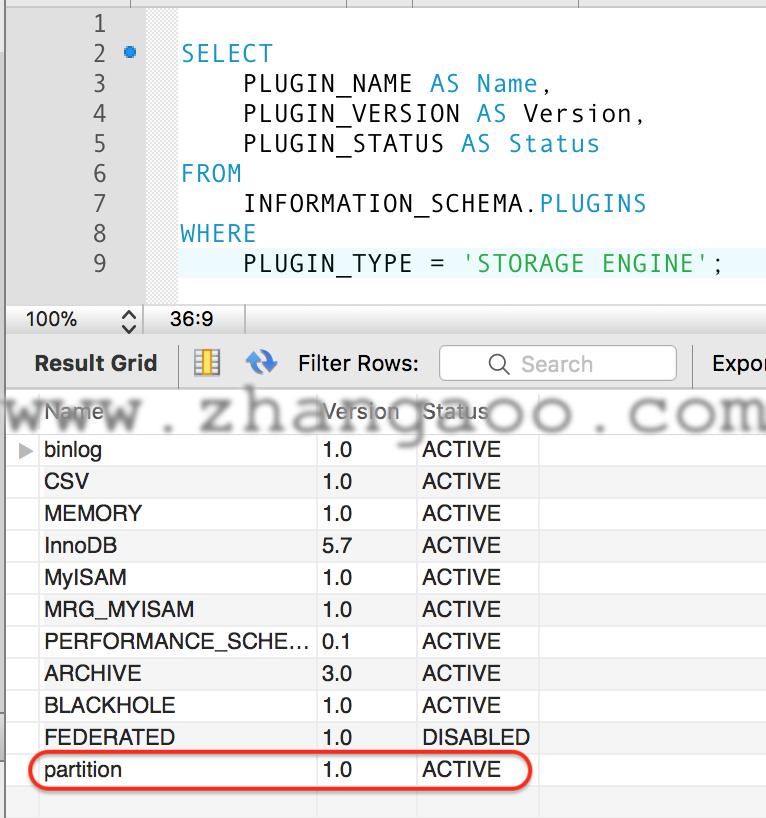
环境检查
SELECT
PLUGIN_NAME AS Name,
PLUGIN_VERSION AS Version,
PLUGIN_STATUS AS Status
FROM
INFORMATION_SCHEMA.PLUGINS
WHERE
PLUGIN_TYPE = 'STORAGE ENGINE';
结果如图:
新建分区表
使用当前报表库中数据最多的表st_daily_part_stock进行测试,因为报表都含有时间字段,查询的SQL中也一定会包含时间字段,使用时间字段分区顺理成章。这里使用比较方便的列分区,当然范围分区也是可以的。分区SQL如下下:
CREATE TABLE `st_daily_part_stock_partition` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`id_date_dim` int(11) NOT NULL COMMENT '日期维度',
`id_part_dim` int(11) NOT NULL COMMENT '材料维度',
`id_storage_dim` int(11) NOT NULL COMMENT '仓库维度外键',
`out_number` decimal(18,2) DEFAULT NULL COMMENT '出库数量',
`creationtime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',
`modifiedtime` datetime NOT NULL COMMENT '记录更新时间',
PRIMARY KEY (`id`,`id_date_dim`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='出入库明细事实表'
PARTITION BY RANGE COLUMNS(id_date_dim)
(PARTITION p0 VALUES LESS THAN (1309) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (1340) ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN (1370) ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (1401) ENGINE = InnoDB,
PARTITION p4 VALUES LESS THAN (1431) ENGINE = InnoDB,
PARTITION p5 VALUES LESS THAN (MAXVALUE) ENGINE = InnoDB);
注意这里是联合主键,分区字段id_date_dim包含在其中,原因如上规则。
分区表基本测试
创建了st_daily_part_stock_partition分区表,同时也创建了st_daily_part_stock供对照,st_daily_part_stock除了没有进行分区其他表结构和数据量两个表都一致,28007743条数据。
在《高性能MySQL》中看到基准测试的概念,使用了书中两个shell工具,抓取了一些测试性能数据,还有好多高级工具比如sysbench没来得及使用。如下:
导入数据测试
两个表在大致相同的环境下,在我本机导入4.9G数据,花费时间接近约为12分钟左右,搜集的数据中还包含MySQL的load、QPS等信息。
全表SELECT COUNT(*)测试
查询未分区表:
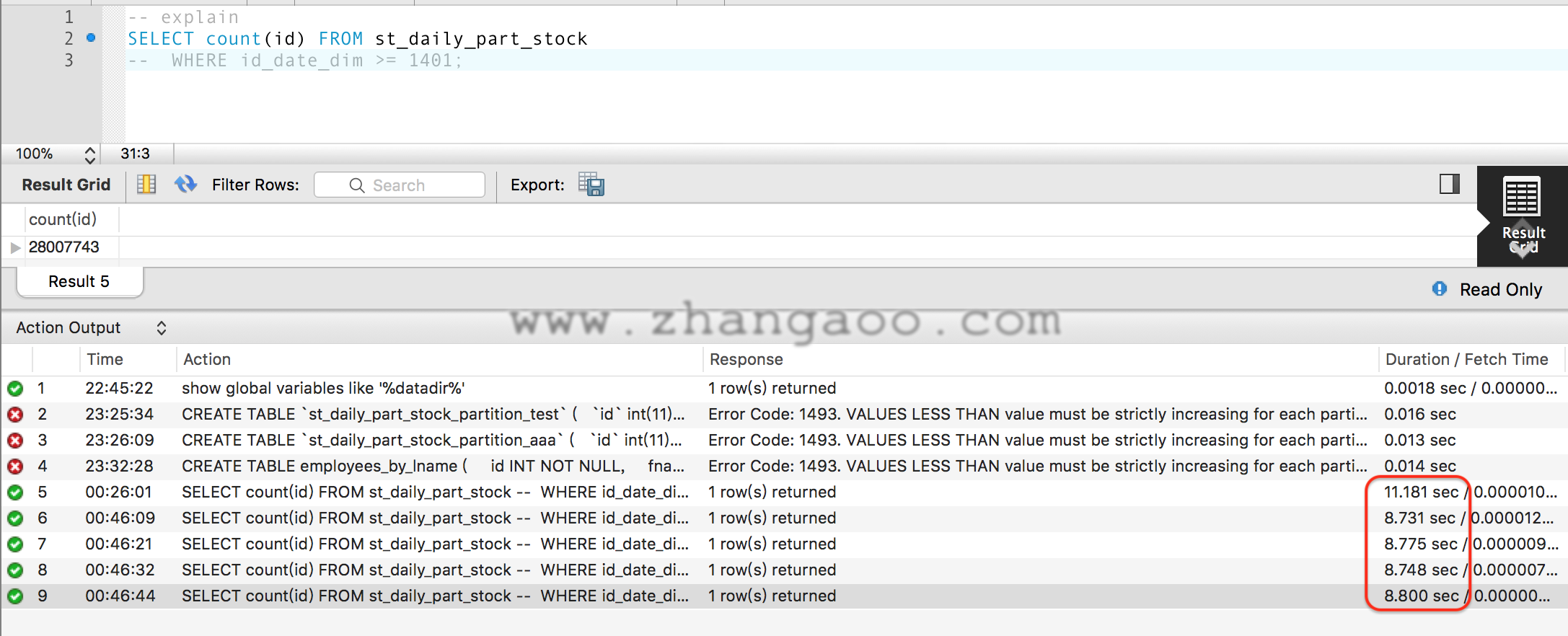 查询分区表:
查询分区表:
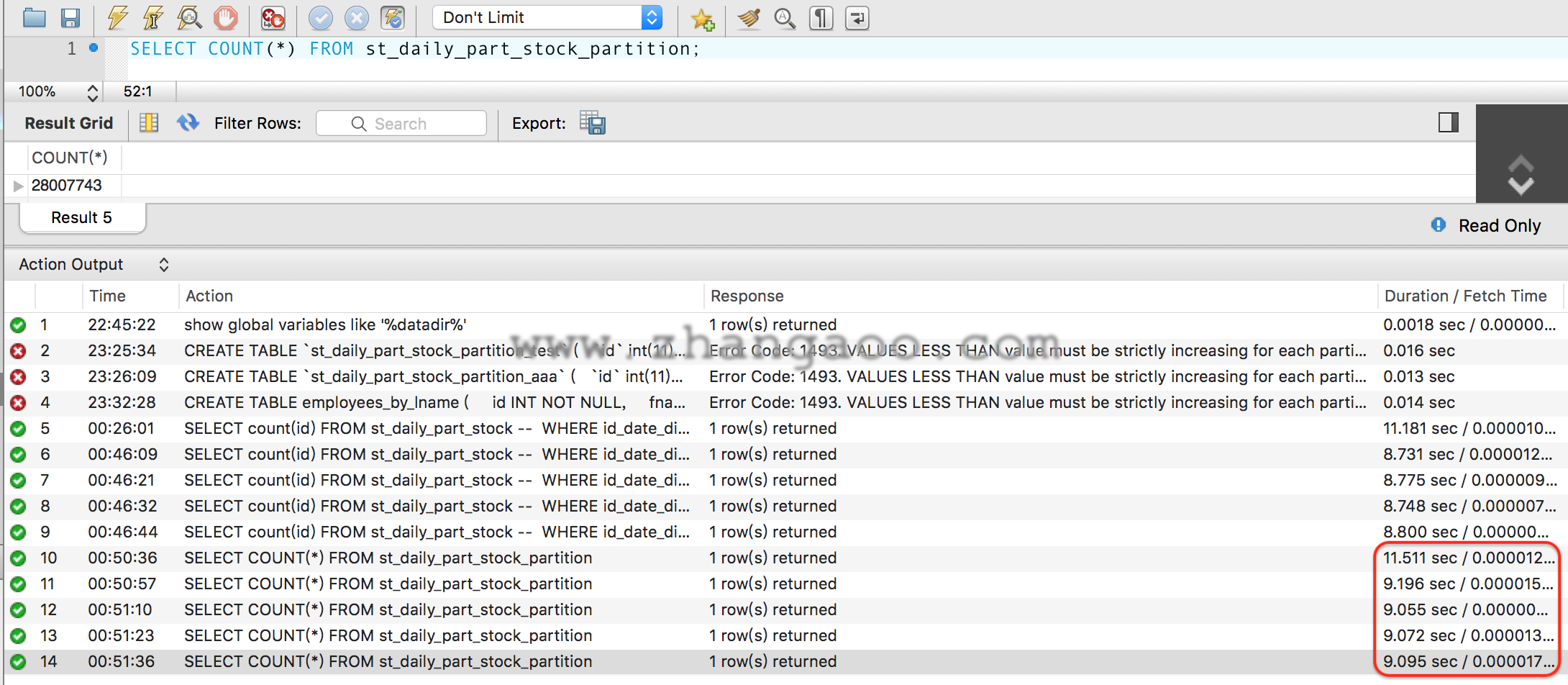 可以看到表分区后查询时间还略慢于未分区的情况。
可以看到表分区后查询时间还略慢于未分区的情况。
 按理说表分区后扫描小分区的速度应该元快于全表扫描,然后把分割分区的结果相加,应该也要更快才对。但事实上MySQL目前并没有这么实现,官网找到下面的说明。
按理说表分区后扫描小分区的速度应该元快于全表扫描,然后把分割分区的结果相加,应该也要更快才对。但事实上MySQL目前并没有这么实现,官网找到下面的说明。
Other benefits usually associated with partitioning include those in the following list. These features are not currently implemented in MySQL Partitioning, but are high on our list of priorities. Queries involving aggregate functions such as SUM() and COUNT() can easily be parallelized. A simple example of such a query might beSELECT salesperson_id,COUNT(orders) as order_total FROM sales GROUP BY salesperson_id;. By “parallelized,” we mean that the query can be run simultaneously on each partition, and the final result obtained merely by summing the results obtained for all partitions.
大概意思是说“目前的MySQL版本还没实现SUM() and COUNT()在多分区表的情况下并行执行,然后把执行的结果累加,但是这些功能已经在计划中,并且优先级很高。”
部分数据SELECT COUNT(*)测试
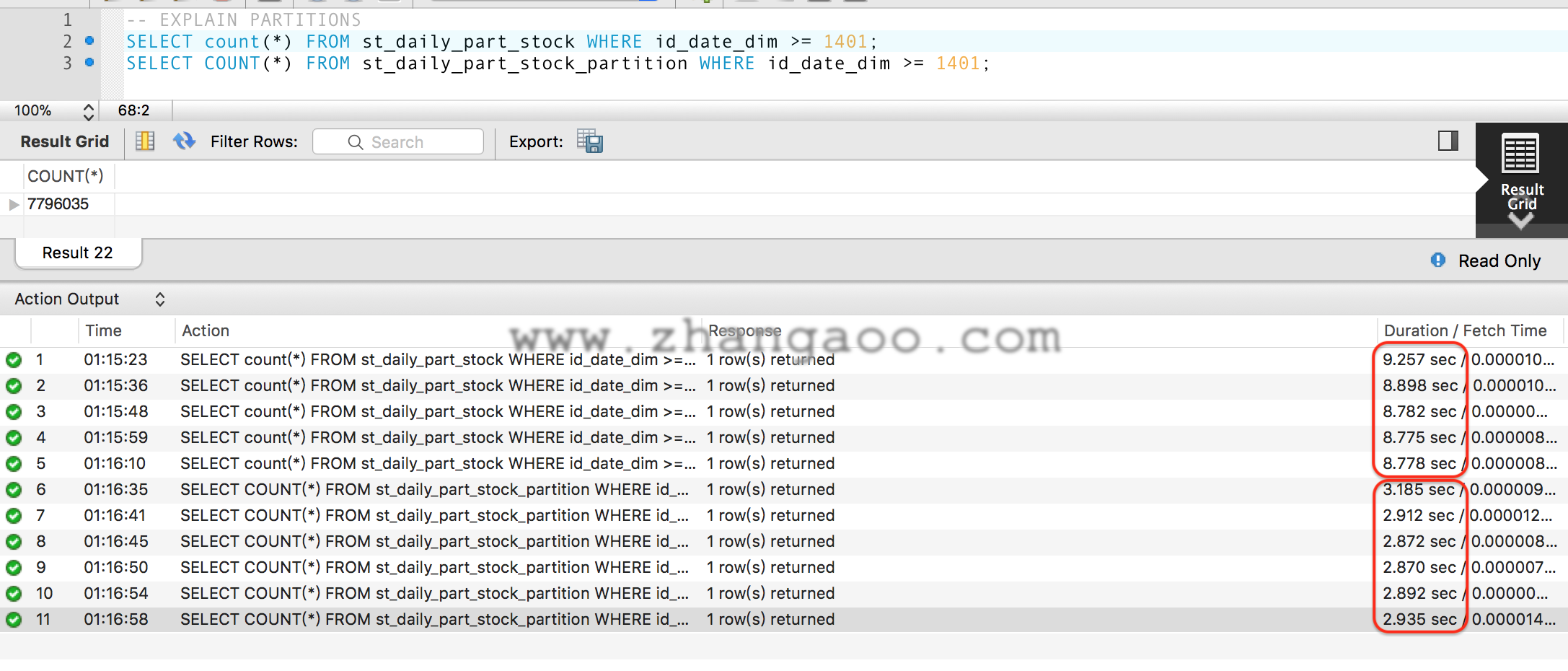 看一下执行计划
未分区
看一下执行计划
未分区
 分区
分区
 分区数据分布情况
分区数据分布情况
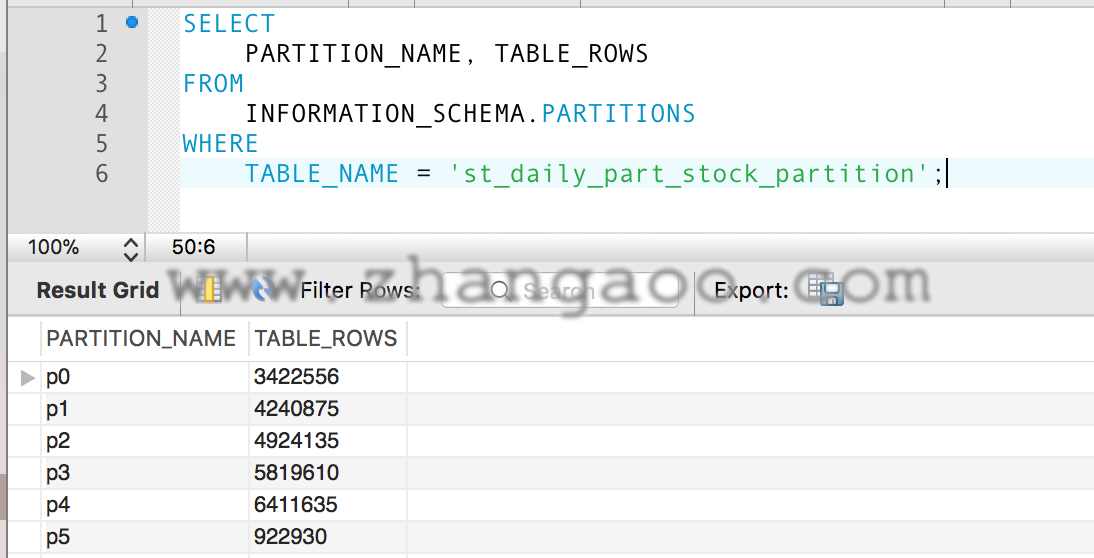 结论:在过滤条件中含有分区信息时,MySQL会自动过滤掉不相关的区间,这样扫描数据量就大大减小,速度也就上来了。我们目前的报表业务,就很符合这种场景,热点数据仅仅分布在最近的1-3月。
结论:在过滤条件中含有分区信息时,MySQL会自动过滤掉不相关的区间,这样扫描数据量就大大减小,速度也就上来了。我们目前的报表业务,就很符合这种场景,热点数据仅仅分布在最近的1-3月。
数据更新测试
目前报表数据更新的场景是,每天的增量更新,再集计的话可能会更新多天的数据,最坏的情况就是月末可能会跨月更新几天的数据。为了测试假设我们一次1个月的数据,更细7月份的数据。数据量大概380W。 不分区
-- # id, date
-- 1309, 2017-08-01
UPDATE st_daily_part_stock SET creationtime=NOW() WHERE id_date_dim < 1309;
分区
-- # id, date
-- 1309, 2017-08-01
UPDATE st_daily_part_stock_partition SET creationtime=NOW() WHERE id_date_dim < 1309;
结果

删除数据测试
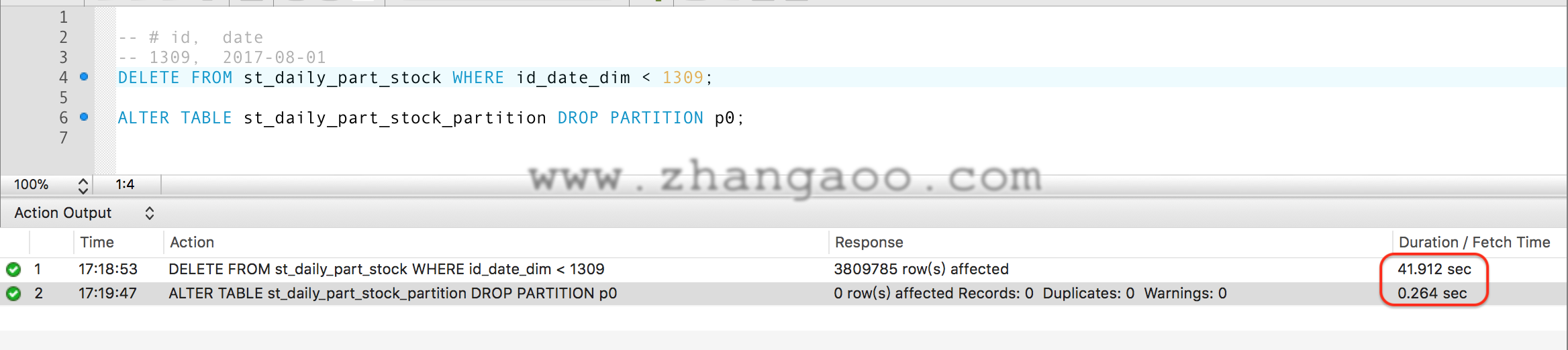
现在报表的实际场景,会有删除旧数据的需求,比如删除7月份的数据。 不分区
-- # id, date
-- 1309, 2017-08-01
DELETE FROM st_daily_part_stock WHERE id_date_dim < 1309;
分区 目前分区就是按时间来的,每个月一个分区,因此只需要删除一个分区
ALTER TABLE st_daily_part_stock_partition DROP PARTITION p0;
结果
分区拆分测试
初始新建分区往往难以精确判断未来分区的数据量,随着业务和时间的变化,某些分区数据可能会很多各个分区之间数据不太均衡。这种情况就需要人工调整分区的大小,把大分区拆分成多个小分区,多个数据较少的小分区合并成数据相对合理的分区。 当前分区数量分布如下:
# PARTITION_NAME, TABLE_ROWS
p1, 4240875
p2, 4924135
p3, 5819610
p4, 6411635
p5, 1552360
我们尝试把p4分区拆成两个小分区分别为p41、p42,SQL如下:
ALTER TABLE st_daily_part_stock_partition REORGANIZE PARTITION p4 INTO (
PARTITION p41 VALUES LESS THAN (1416),
PARTITION p42 VALUES LESS THAN (1431)
);
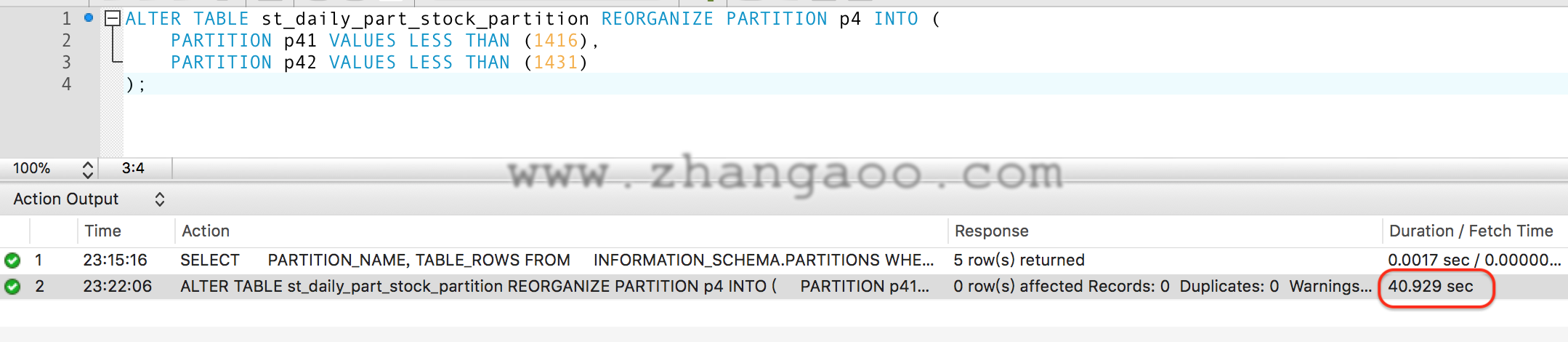 查看一下当前分区情况
查看一下当前分区情况
# PARTITION_NAME, TABLE_ROWS
p1, 4240875
p2, 4924135
p3, 5819610
p41, 0
p42, 0
p5, 1552360
分区速度比我预想的要快,可能是由于每个分区都是独立的磁盘数据文件,因此数据只涉及到部分数据。但是令我最惊讶的是数据没了,原本以为再分区数据会自动拷贝到各自的新分区。
No data is lost in splitting or merging partitions using REORGANIZE PARTITION. In executing the above statement, MySQL moves all of the records that were stored in partitions s0 and s1 into partition p0.
使用REORGANIZE PARTITION语法,MySQL官网明明说数据是不会丢的,这让我很疑惑。
然后我SELECT COUNT(*)了一下
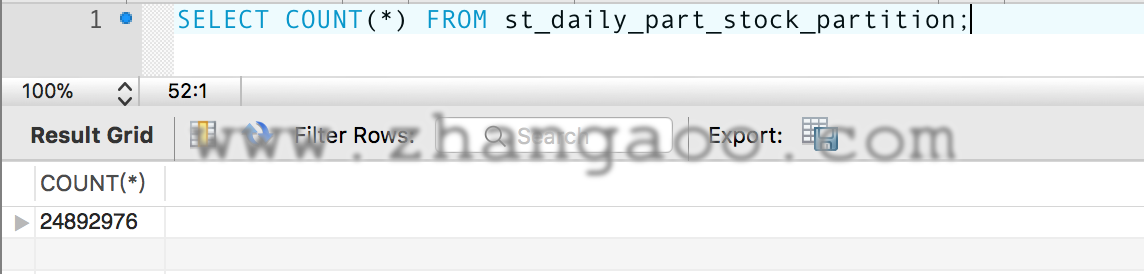
4240875+4924135+5819610+1552360=16536980
简直了,分区数量和COUNT(*)值竟然不等,进一步确认一下重新分区后p4分区的数据还在不在
 发现数据的确还在,但数量上好像有点差异,看来重建分区后有些数据已经不准了,可能是缓存数据吧。那么应该有对应的刷新机制。
果不其然Google了一下,别人也遇到了类似的问题,原因是以下语句的统计信息并不会实时更新
发现数据的确还在,但数量上好像有点差异,看来重建分区后有些数据已经不准了,可能是缓存数据吧。那么应该有对应的刷新机制。
果不其然Google了一下,别人也遇到了类似的问题,原因是以下语句的统计信息并不会实时更新
SELECT
PARTITION_NAME, TABLE_ROWS
FROM
INFORMATION_SCHEMA.PARTITIONS
WHERE
TABLE_NAME = 'st_daily_part_stock_partition';
需要执行下面的SQL语句才能刷新再分区后表的统计信息
ALTER TABLE st_daily_part_stock_partition ANALYZE PARTITION p41;
ALTER TABLE st_daily_part_stock_partition ANALYZE PARTITION p42;
# PARTITION_NAME, TABLE_ROWS
p1, 4240875
p2, 4924135
p3, 5819610
p41, 3227256
p42, 3365449
p5, 1552360
4240875+4924135+5819610+3227256+3365449+1552360=23129685
但是分区累计和COUNT(*)值还是不相等,干脆把剩余的分区都ANALYZE一下,结果如下:
# PARTITION_NAME, TABLE_ROWS
p1, 4801744
p2, 5187635
p3, 6196330
p41, 3227256
p42, 3365449
p5, 1587571
4801744+5187635+6196330+3227256+3365449+1587571=24365985
但是发现这个值和COUNT()还是不等,并且每次ANALYZE每个分区值的总计都会变,但COUNT()每个分区值都是一样的,猜测这个统计的数据应该是个大概值,就和查询计划中的数据类似。
分区合并测试
拆分的逆操作就是合并,如果存在很多的空闲分区,分区的功能就得不到应有的发挥,同时管理众多小分区也会损耗一定的性能。因此可能会在定期合并一些小的分区。以上面的拆分为例,把拆分的两个分区p41和p42合并为p4。 分区合并SQL如下:
ALTER TABLE st_daily_part_stock_partition REORGANIZE PARTITION p41,p42 INTO (
PARTITION p4 VALUES LESS THAN (1431)
);

# PARTITION_NAME, TABLE_ROWS
p1, 4801744
p2, 5187635
p3, 6196330
p4, 6762460
p5, 1587571
分析 可见合并和拆分的效率几乎是一样的,合并两个300w的表和拆分一个600W的表时间都是40s左右。合并后也执行一下ANALYZE PARTITION,否则查询分区数据量可能还是0和上面一致。COUNT(*)操作数据不受影响。
分区表的特点
优点
1、在查询的WHERE条件中增加分区信心可以有效过滤分区,极大的优化某些查询。
2、分区表在创建分区表后可以更改,因此可以重新组织数据,以增强在分区方案首次建立时可能不经常使用的频繁查询。
3、每个分区可以给数据文件和索引文件制定一个目录,这些目录所在的物理磁盘分区可能也都是完全独立的,可以提高磁盘IO吞吐量。
4、 通过删除一个或多个分区来删除无用数据,使删除变得更简单。相反,在某些情况下添加新数据的过程可以通过添加一个或多个新分区来专门存储该数据而得到极大的便利。
缺点
1、目前应用中的大部分表都有主键,受限于分区表达式的规则,往往需要重新建表结构,这有可能是会影响现有业务逻辑的。
2、分区表的实现机制有而外的开销,当分区表很多时,开销会越来越大。“根据实际经验对于大多数系统100个左右的分区是没问题的”摘自《高性能MySQL》。
3、打开并锁住所有底层表的成本可能很高,当查询分区表的时候,MySQL需要打开并锁住所有的底层表,这是分区表的另外一个开销。
4、维护分区的成本可能会很高,新增、删除分区速度会很快。但是重组或ALERT分区表时,会先创建一个临时分区,然后将数据复制到其中,再删除原分区。
参考资料
- dev.mysql.com partitioning
- 《高性能MySQL》
本文由 zealzhangz 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为:
2017/12/14 23:50
